2026 年 3 月,全球 AI 產業迎來一次重大轉折——中國人工智能實驗室 DeepSeek 即將發布其第四代旗艦模型 DeepSeek V4。這款擁有約一萬億參數的多模態 AI 模型,不僅能處理文字,更原生支持圖片、影片與文本生成,標誌著 AI 技術從「單一文字」邁向「全方位感知」的關鍵一步。
對於香港企業而言,DeepSeek V4 是什麼?它不只是一個技術名詞,更是一個可能徹底改變業務運營方式的工具。本文將深入剖析 DeepSeek V4 的核心技術架構、與前代的差異,以及它對香港企業帶來的五大實際影響,助你在 AI 浪潮中搶佔先機。

DeepSeek V4 的核心技術規格
要理解 DeepSeek V4 是什麼,首先需要認識它在技術層面的突破。以下是已知的關鍵規格:
一萬億參數的 MoE 架構
DeepSeek V4 採用混合專家(Mixture of Experts,MoE)架構,總參數量約達一萬億。然而,模型在推理時每次僅啟動約 320 億個參數,這意味著在保持極高智能水平的同時,運算成本遠低於傳統的密集模型。相比前代 DeepSeek V3 的 6,710 億參數,V4 在規模上實現了近 50% 的跨越。
原生多模態能力
與過往以文字處理為主的版本不同,DeepSeek V4 是一款原生多模態 AI 模型,從預訓練階段便同時整合了文字、圖像及影片的生成能力。用戶可以直接透過文字指令生成高質量圖片或影片,無需依賴額外的外掛工具。
百萬級上下文窗口
DeepSeek V4 支持高達一百萬 token 的上下文窗口,較 V3 系列的 128K 提升近八倍。這意味著模型可以一次性處理超長文件、整個程式碼庫 or 大量對話記錄,大幅提升在企業級應用中的實用性。
Engram 記憶體架構:DeepSeek V4 最大的技術革新
在眾多技術創新中,Engram 記憶體架構被業界公認為 DeepSeek V4 最具突破性的設計。這項由 DeepSeek 與北京大學於 2026 年 1 月聯合發布的技術,從根本上改變了 AI 模型處理知識的方式。
為何傳統架構存在問題?
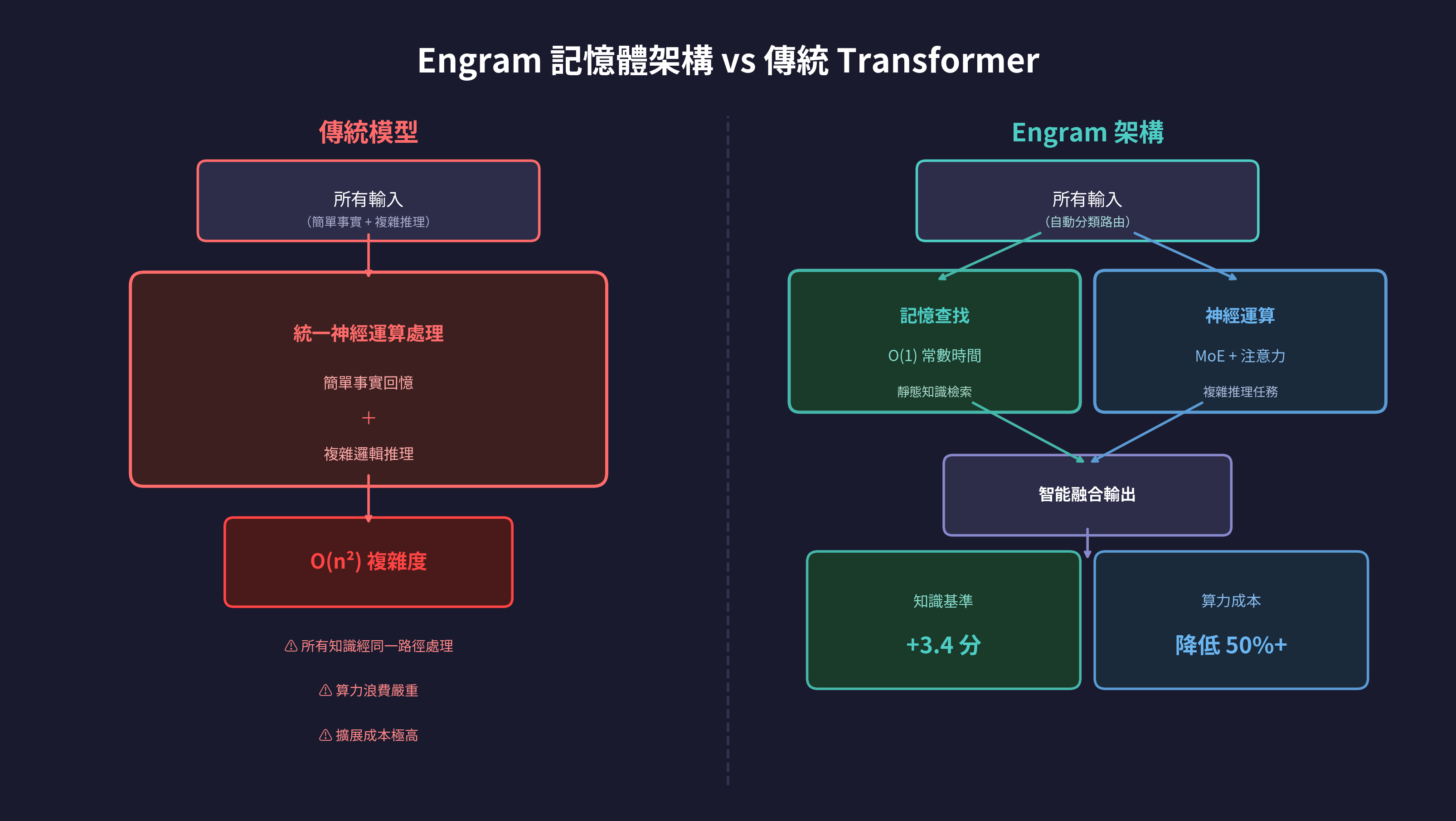
傳統的 Transformer 模型將所有知識壓縮在神經網絡的權重之中。無論是回答「法國首都是巴黎」這類簡單事實,還是解決一道複雜的數學推理題,模型都必須經過同樣高成本的神經運算過程。這種「一視同仁」的方式,在模型規模擴展至萬億參數時,會造成極大的算力浪費。
Engram 的核心理念:將記憶與推理分離
Engram 記憶體架構的前提簡潔而優雅——並非所有知識都需要神經運算。靜態事實和已確立的模式可以儲存在一個互補的記憶系統中,在需要時高效檢索,正如人類不會每次都重新計算「2+2=4」,而是直接回憶結果。
Engram 透過一個現代化的 N-gram 查找模組,以 O(1) 常數時間完成檢索——無論儲存的資訊量多大,檢索速度始終恒定。這在架構上形成了根本性的分離:
- 神經運算(注意力機制與 MoE):負責複雜推理、新知識合成、語境相關處理
- 記憶查找(Engram):負責靜態知識、既有模式、事實回溯
研究團隊更發現了一條 U 型擴展定律:將約 75% 的參數分配給推理、25% 分配給記憶查找,可達到最佳性能。實驗證明,Engram 在不增加算力的情況下,將知識基準 MMLU 提升了 3.4 分,同時因為釋放了淺層網絡的容量,深層網絡得以更專注於程式碼和數學等複雜邏輯任務。
記憶體卸載:突破 GPU 限制
Engram 還有一項重要的工程優勢:研究人員成功將一千億參數規模的嵌入表卸載到主機 DRAM 中,吞吐量損失低於 3%。這意味著模型可以在不依賴昂貴 GPU 高帶寬記憶體的情況下進行擴展,顯著降低了部署成本。
DeepSeek V4 與前代及競爭對手的對比
要全面理解 DeepSeek V4 是什麼,將其與前代版本及市場上的競爭對手進行對比至關重要:
| 比較維度 | DeepSeek V3 | DeepSeek V4 | GPT-4 / Claude |
|---|---|---|---|
| 總參數量 | 6,710 億 | 約 1 萬億 | 未公開 |
| 推理啟動參數 | 370 億 | 約 320 億 | 未公開 |
| 上下文窗口 | 128K token | 100 萬 token | 128K-200K |
| 多模態能力 | 僅文字 | 原生圖文影片 | 圖文(部分影片) |
| 記憶體架構 | 傳統 Transformer | Engram O(1) 查找 | 傳統 Transformer |
| 開源 | 是 | 是 | 否 |
| API 成本 | 低 | 極低(傳聞便宜 50 倍) | 高 |
從表格可見,DeepSeek V4 在多個維度上均實現了質的飛躍。尤其值得注意的是,作為開源 AI 模型,V4 將模型權重完全公開,讓全球開發者與企業都能自由使用和調整,這與 OpenAI 和 Anthropic 的閉源策略形成鮮明對比。
DeepSeek V4 對香港企業的 5 大影響
了解 DeepSeek V4 是什麼之後,更重要的是認識它將如何改變香港的商業格局。以下是五個最值得關注的實際影響:

影響一:大幅降低 AI 工具應用門檻
過往,企業導入高端 AI 技術往往需要高昂的 API 費用或自行部署大規模伺服器。DeepSeek V4 作為開源 AI 模型,不僅免除了授權費用,其 MoE 架構更讓推理成本大幅降低。根據業界傳聞,V4 的 API 成本可能較 GPT-4 便宜超過 50 倍。
對香港的中小企業而言,這意味著原本只有大型機構才能負擔的AI 工具應用——例如智能客服、自動化報告生成、多語言翻譯——將變得觸手可及。一家本地零售商可能只需每月數十美元,便能部署一套涵蓋文字與圖像生成的 AI 助手。
影響二:多模態能力重塑內容行銷策略
DeepSeek V4 的原生多模態 AI 模型能力,讓企業可以透過單一平台同時生成文案、產品圖片甚至短影片。這對香港高度依賴數碼營銷的商業環境尤其重要。
想像一家電商企業,過去需要分別聘請文案撰寫員、平面設計師和影片製作人來完成一次產品推廣。借助 DeepSeek V4,營銷團隊可以在數分鐘內生成包含文案、配圖和產品展示影片的完整素材,大幅縮短從創意到發布的週期。
影響三:百萬級上下文窗口提升專業服務效率
香港作為國際金融中心和法律服務樞紐,專業人士經常需要處理大量的合約文件、財務報告和法規文本。DeepSeek V4 的一百萬 token 上下文窗口,讓模型可以一次性讀取並分析數百頁的文件,遠超現有工具的處理能力。
例如,一位律師可以將整套交易文件(包括主合約、附件、往來書信)全部輸入模型,要求其提取關鍵條款和潛在風險點。一位會計師則可以將全年財務數據一次性交由模型分析,快速生成合規報告。這種效率提升對於以「時間計費」為主的專業服務行業,意味著顯著的成本優勢。
影響四:編程能力強化軟件開發生態
據路透社和 The Information 報道,DeepSeek V4 經過針對編程和長上下文軟件工程任務的專門優化,內部測試顯示其在長上下文編程任務中可能超越 Claude 和 ChatGPT。洩露的基準測試數據亦顯示,V4 在 HumanEval 上達到約 90% 的成績(Claude 為 88%,GPT-4 為 82%),在 SWE-bench Verified 上超過 80%。
對香港的科技公司和初創企業而言,這意味著開發團隊可以借助 V4 大幅提升代碼審查、重構和自動化測試的效率。尤其是在處理大型遺留代碼庫時,V4 的長上下文能力允許開發者將整個專案結構一次性提交分析,獲得跨文件的一致性建議。
影響五:地緣政治格局下的戰略考量
DeepSeek V4 的發布帶有明確的地緣政治訊號。據路透社報道,DeepSeek 此次打破業界慣例,未向美國晶片製造商 Nvidia 和 AMD 提供 V4 的早期優化權限,轉而優先與華為、寒武紀等中國本土晶片供應商合作。
對於香港企業而言,這一動向帶來雙重啟示。首先,隨着 AI 模型逐步適配非 Nvidia 的國產晶片,未來部署開源模型的硬件選擇將更加多元,有助於降低對單一供應商的依賴。其次,在中美科技博弈持續升溫的背景下,選擇 AI 供應商時需要更審慎地評估合規風險與供應鏈穩定性。作為同時連接內地與國際市場的橋樑,香港企業在制定 AI 策略時應兼顧兩方面的因素。
如何為 DeepSeek V4 的到來做好準備?
面對即將到來的 DeepSeek V4,香港企業可以從以下幾個方面着手準備:
- 盤點現有 AI 使用場景:梳理目前業務中哪些環節已在使用或可以使用 AI 工具,評估 V4 的多模態 and 長上下文能力可以帶來哪些具體改善。
- 建立評估框架:在 V4 正式發布後,針對自身業務場景進行測試,比較其與現有工具(如 GPT-4、Claude)的實際表現差異,而非僅依賴基準測試分數。
- 關注開源社區動態:DeepSeek 預計在發布時提供簡要技術說明,約一個月後公開完整工程報告。持續追蹤社區的實測反饋,有助於更快判斷 V4 是否適合引入實際生產環境。
- 提升團隊 AI 素養:無論選擇哪一款AI 工具應用,團隊的 AI 知識水平都是決定成效的關鍵。投資於員工的 AI 培訓,確保團隊具備基本的提示工程和工作流程設計能力。
總結:DeepSeek V4 代表 AI 產業的新拐點
DeepSeek V4 是什麼?它是一款集一萬億參數、原生多模態能力、Engram 記憶體架構和百萬級上下文窗口於一身的下一代開源 AI 模型。從技術層面看,它代表了 AI 架構從「暴力堆疊算力」向「智能分配資源」的典範轉移;從商業層面看,它將高端 AI 能力的使用門檻降至前所未有的水平。
對香港企業而言,DeepSeek V4 的到來不僅是一次技術升級的機會,更是重新審視整體 AI 策略的契機。無論你是希望降低營銷成本的中小企業主、尋求提升效率的專業人士,還是正在建構 AI 原生產品的科技創業者,現在正是深入了解並做好準備的最佳時機。
如果你希望系統性地掌握 AI 工具的實戰應用方法,歡迎了解我們的人工智能課程。課程涵蓋從基礎概念到進階應用的完整內容,助你將 AI 技術切實融入日常工作與業務決策之中。